

Running RVC Models on the Easy GUI
How to run this on Colab after Google Banned Gradio UIs

Greetings and salutations, tech enthusiasts!
Welcome back to Dubverse Black where we provide you an overdose of mind-blowing information about the world of technology. Today, we’re dishing out some piping hot insights on how to effectively train your own models on Retrieval-based Voice Conversion (RVC). Better late than never, right?
Let's buckle up and dive straight into two key topics for today:
Dodging Google Colab timeout/bans like a ninja, and
Our secret recipes for modelling greatness (No, we're not sharing our grandma's pickle recipe.)
Time for a quick tech breakdown!

“RVC, tell me what you are…”
Retrieval-based Voice Conversion (RVC) is a tech wizard! It uses a deep neural network to sprinkle its magic and transform one voice into another, based on the VITS model. This model is an impressive creation in the realm of end-to-end text-to-speech systems. RVC has a myriad of stellar qualities making it a must-have on a tech enthusiast's list!
Here they are:
Speed Demon: RVC can work its magic in real-time. Ever wished to sound like your favourite celebrity? It’s now just a click away!
Doppelgänger Audio: Ready to clone voices? Who wouldn’t love to sound like their favorite pop-star?
Economical: Availing RVC technology by means of free PC voice changers is a budget-friendly deal.
Minimalist: Works perfectly with just 10 minutes of low noise speech.
All right, that's enough chit-chat. Let's get the ball rolling!
“RVC on Google Colab? Tell me how!”
With several guides hovering on the internet, trust us as we found the easiest way to use the RVC notebook. Simply connect this notebook to a custom GCE runtime (we used v100 and 32GB ram) and activate the UI cell.
Quick tip – commenting out line 5 of the GUI cell will fake a drive that you can always bank on. There are anyways issues with drive auth on custom runtimes.
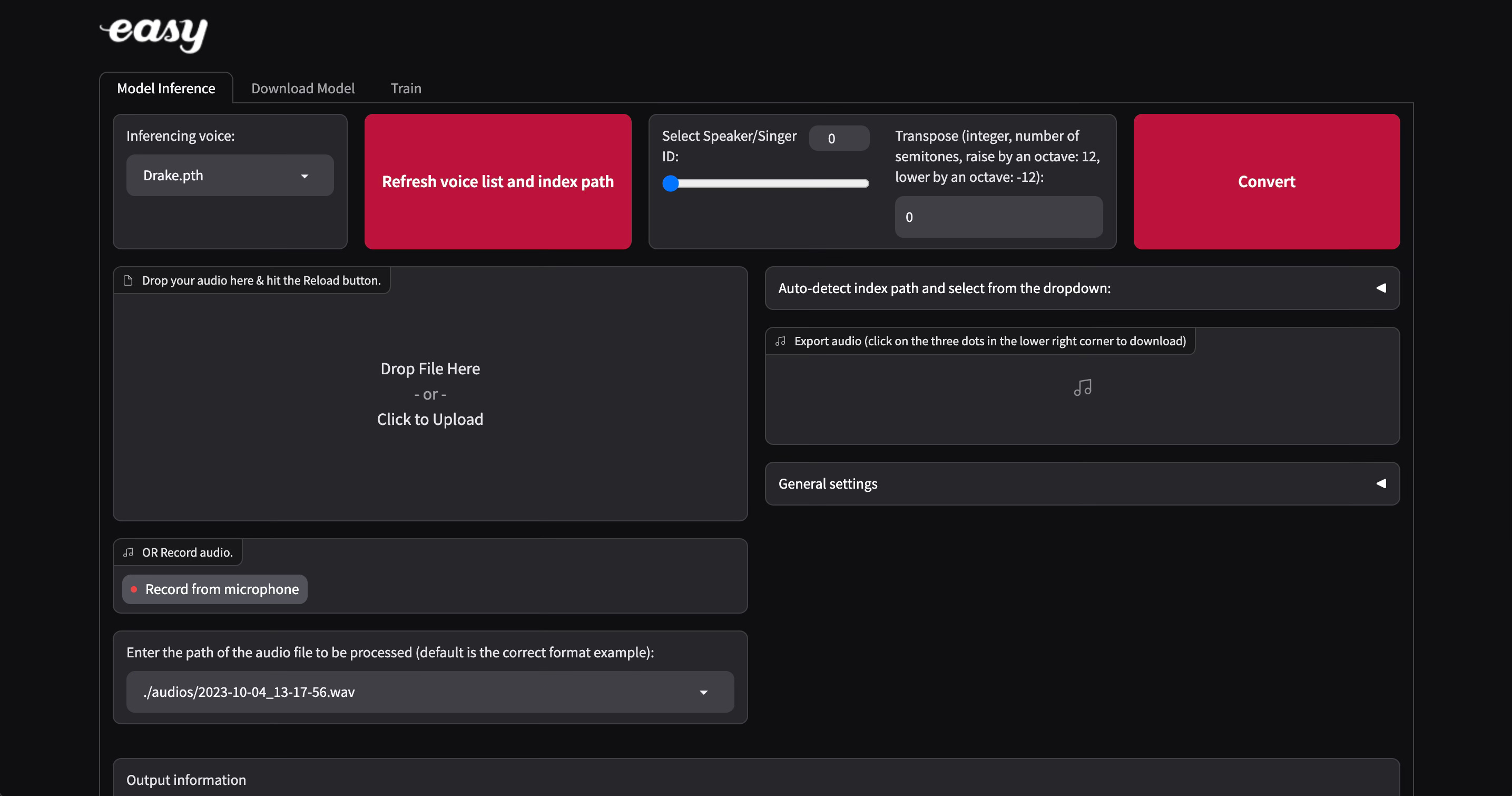
Time to prepare your data feast!
We need approximately 15 minutes of filtered vocals (avoid keyboard clicks, applauses, background noise, etc) preferably from interviews. If the interview involves one-on-one engagement (think news interviews / podcasts), that's your golden opportunity. If the audience takes a slice of the conversation, apply a hum reduction filter and a noise cancellation filter on the audio. iMovie worked wonders for this!
Crafting the Input Dataset:
Let's say you’re a fan of Amitabh Bachchan. Create an experiment folder in the name of your chosen celebrity as such /content/datasets/amitabh.
Don't sweat the small stuff! Whether you use smaller audio segments or a 40-minute monologue audio in the /content/datasets/category, upload it easily from the Colab side navigation. Then open the Gradio link and switch to the 'train' tab, name your experiment (the code uses this name to refer to your models). Click on 'process data' and ignore any RuntimeError. Wait for a couple of minutes till the logs announce “end preprocess”.

Extracting Features is an art, let’s perfect it

Harvest focuses on pitch in studio audio and it takes around 400 training steps. On the other hand, rmvpe_gpu works on any other audio aiming to create a similar voice and minimising the overall error. It takes around 600 training steps. Hence, training duration depends on the data type.
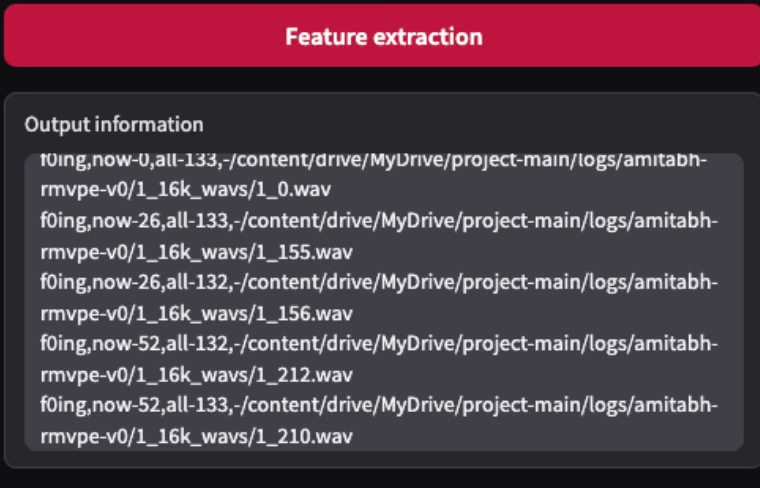
Double check /content/drive/MyDrive/project-main/logs/amitabh-rmvpe-v0/1_16k_wavs/ and see some 500-600 files exist there.
The Final Sprint
Tap on 'Train feature index', which should be done in 5 mins. Choose epochs as per the extracting features section and let the training begin! If there are any issues of shared memory running out, follow this answer on Stackoverflow to increase it to 20G and you’re good to go!
Sample Outputs
Here’s a sample of Rani Mukherjee singing “Billo Bagge”
and here’s a sample of Amitabh Bacchan delivering the famous “70 minute hai tumhare paas” speech from ChakDe India.
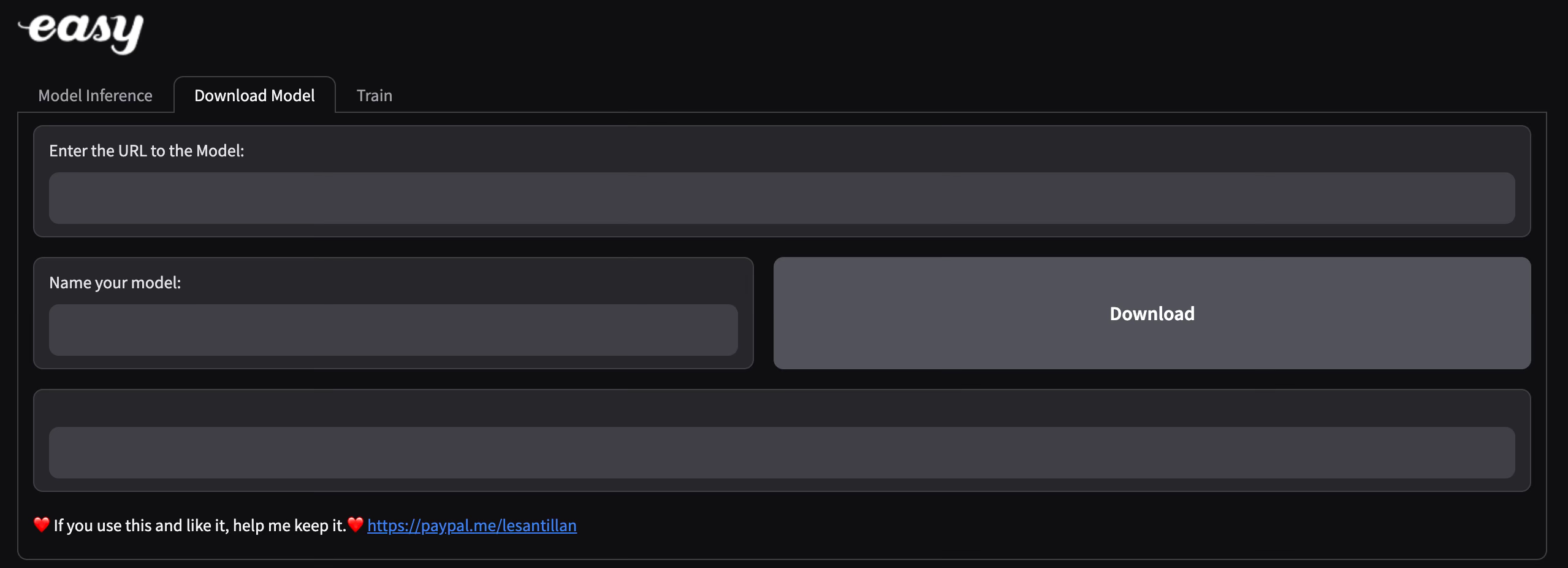
Pre-trained Models
If you are lazy like me and would want to play with something that’s right off the shelf, please use the “Download Model” tab on Gradio UI and get the model links from here.
Every learning session should be enjoyable and educational; we hope this blog was both!
Join our Discord community to get the scoop on the latest in Audio Generative AI!
Until next time, keep exploring and innovating!
WithoutWax,
Tanay