

Pioneering Translation Benchmarking with LLMs
NMT for Indic LLMs?


Welcome to another edition of Dubverse Black where we benchmark various Machine Translation (MT) methodologies, focusing on their effectiveness in translating timestamp-wise audio transcriptions. This challenging and increasingly relevant task not only requires the accurate translation of spoken language but also the preservation of temporal information, critical for context and coherence.
Our benchmarking exercise assesses state-of-the-art Large Language Models (LLMs) and non-LLM techniques to evaluate their proficiency in handling these complexities.
Data and Models Tested
The primary focus of our exercise is on English to Hindi translations, leveraging the Sarvam.AI OpenHathi model, which is fine-tuned only on English, Hindi, and Hinglish data. The models tested in this exercise are -
Sarvam.AI OpenHathi v0.1
IndicTrans v2
LLaMA-2-7b-chat.
These models are evaluated against ground truth data comprising translations enriched with contextual information using ChatGPT. The dataset used for this exercise is sampled from production Dubverse.ai projects and passes internal metrics that confirm user success on the Dubverse.ai studio. Following are a few examples of the ground truth data.

Evaluation Metrics
To assess the performance of these models, we used quantitative metrics like BLEU, COMET, CHRF, and Length Ratio. These metrics help us understand the accuracy and contextual relevance of the translations produced by the models.
1. BLEU (Bilingual Evaluation Understudy): BLEU is a popular metric for evaluating the quality of text translated by a machine to another language. It compares the machine-translated text to one or more reference translations. BLEU calculates the n-gram precision, which is the proportion of n-grams (a sequence of n words) in the translated text that match the n-grams in the reference text. The BLEU score also includes a brevity penalty to prevent overly short translations. The formula for BLEU is:

Where N is typically 4 (considering up to 4-grams).
2. COMET (Cross-lingual Optimization Metric for Translation Evaluation): COMET is a neural framework for MT evaluation. Unlike BLEU, which is based solely on surface-level text comparison, COMET leverages pre-trained language models to understand the semantics of the translated and reference texts. It assesses translation quality by considering both linguistic adequacy and fluency.
3. CHRF (Character n-gram F-score): CHRF is an evaluation metric that calculates an F-score using character-level n-grams. This makes it effective for languages with less word segmentation. CHRF compares character n-grams between the translated and reference texts and calculates precision, recall, and F-score. The F-score is the harmonic mean of precision and recall:

4. Length Ratio: This metric compares the length of the translated output to the length of the reference translation. It's used to assess whether the translation is too verbose or too concise compared to the reference. A length ratio close to 1 indicates a good match in terms of translation length. This is an important metric that is highly relevant to the dubbing use-case.
These metrics collectively provide a comprehensive view of the translation model's performance, covering aspects like accuracy, fluency, and semantic fidelity.
Prompting Guidelines
Following are the set of prompts we used for fetching translations from the LLM models.
Vanilla OpenHathi prompt
Convert the following line from English to Hindi - \nEnglish: {text} \nHindi: OpenHathi context-enriched prompt
Context - {batch_context} \nConvert the following line from English to Hindi taken from the provided context - \nEnglish: {text} \nHindi: Character-limited OpenHathi prompt
Convert the following line from English to Hindi with no more than {len(text)} characters - \nEnglish: {text} \nHindi: LLaMA-2-7b prompt
[INST]
<<SYS>>
You are a helpful assistant. Provide translations from English to Hindi for the below text in the following specified format -
<</SYS>>
English: {text}
Hindi -
[/INST]Results
Our evaluation revealed that IndicTrans V2, which is an encoder-decoder model, significantly outperforms LLaMA-2-7b-chat in most metrics. However, it's important to note that in cases where IndicTrans V2 scored lower, it often resulted from translations that were correct but differently phrased, especially in instances where the ground truth was in Hinglish. We make this conclusion based on manually verifying the model outputs against corresponding scores.
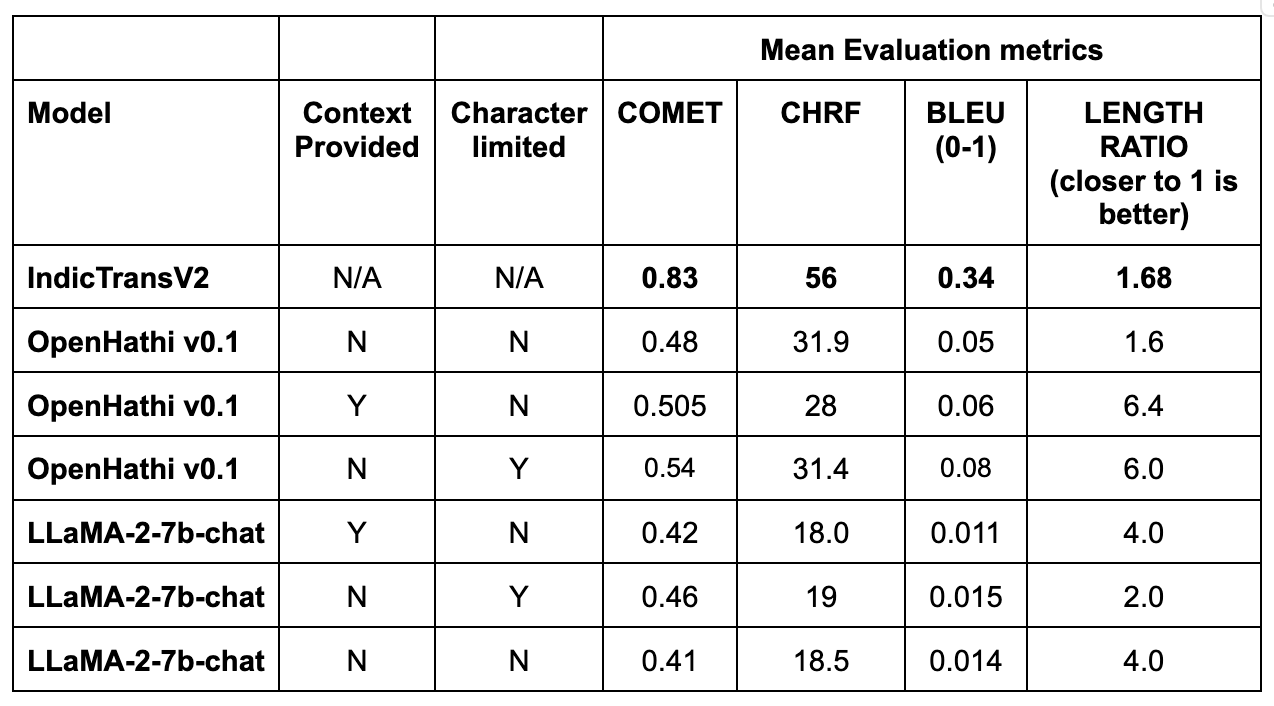
The OpenHathi model, being a base LLM, showed sensitivity to context and often hallucinated when providing translations, indicating a need for fine-tuning for specific tasks. The performance of these models was also measured in terms of GPU memory and compute usage, as well as latency, providing a comprehensive view of their efficiency.

Next Steps
Our findings underscore the importance of fine-tuning and contextual alignment in LLMs for translation tasks. The next steps involve exploring methods like "translate-with-rewrite" and "rewrite-then-translate" using ChatGPT with GPT 3.5 and GPT 4 for contextual prompts and CPS limits.
We aim to further refine our evaluation methods, including the creation of datasets focused on specific topics relevant to our users, and developing new metrics to reduce the need for manual editing. The ultimate goal is to improve our translation systems and evaluate commercially available LLMs for Indian languages, setting a new benchmark in the field of machine translation.
Thanks for reading, will see you with a fine-tuned, RAG enabled Indic LLM soon (iykyk)
Until next time,
WithoutWax
Tanay