

Evals are all we need
voice models are having their "stable diffusion moment"

Voice cloning technology has been with us for a few years, creating waves in various areas with systems like Tacotron and Tacotron2. These innovative inventions worked by recording a voice actor for several hours in a studio, generating a scripted speech. Consequently, an AI model of their voice would be created, and an API provisioned, ideally. However, their application was limited as their realism was far from perfect.
Nevertheless, there's been significant strides in customised architectures that have improved the realism of these AI voices. This technological advancement has opened opportunities in sectors like education for informational video voiceovers, audiobooks, in-game dialogues, personalized message delivery using cloned voices of famous personalities, and even in dubbing, leading to the inception of ventures like Dubverse.
The year 2021 witnessed the term 'synthetic media' or 'deepfakes' become a buzzword. Fast-forwarding to 2023, the rise of Generative AI, especially after the launch of ChatGPT, has been phenomenal. Read our deep dive into the state of the art text-to-speech models below.

In this blog, we'll explore why evaluations are crucial for the continued advancement of this technology, focusing on a unique application of the RVC or Singing AI models.
But, why do we even need evals?
If you're an enthusiast of Stanford's CS231n, like many of us, you're probably familiar with the Imagenet Challenge created by Dr. Fei Fei Li. It was this challenge that offered developers the opportunity to create and evaluate their image detection models to see just how good they were. AlexNet emerged victorious during that challenge.
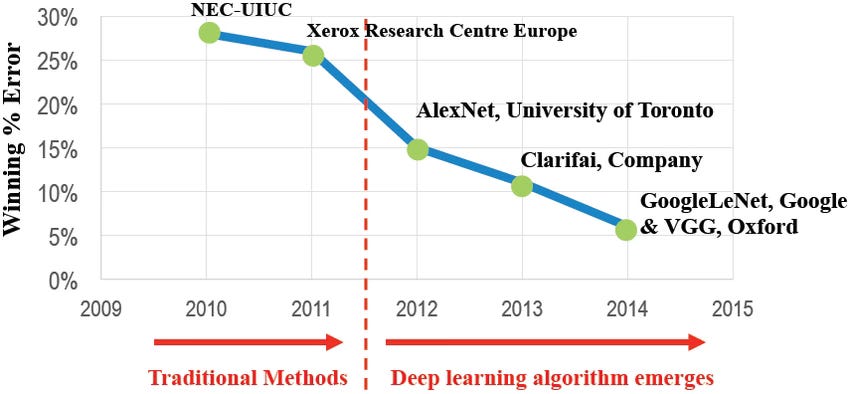
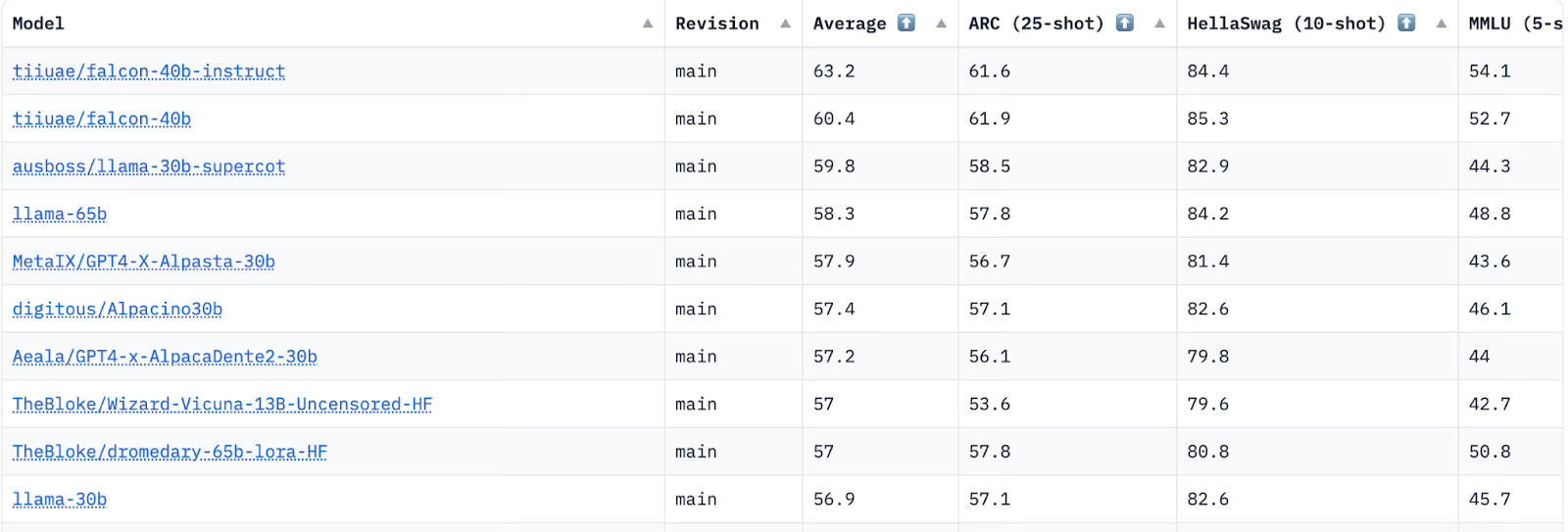
Since the launch of ChatGPT, the open-source community has been buzzing with activity, particularly around the development of Large Language Models (LLMs). There's been ongoing discussion about how certain models are surpassing the performance of GPT 4 on various benchmarks. This includes:
Word Knowledge: Evaluated using MMLU, ARC, etc.
Cognitive Reasoning: Gauged by StrategyQA, COPA, OpenBookQA, etc.
Language Understanding: Assessed via LAMBADA, etc.
Problem Solving: Evaluated through challenges like elementary math QA, LogiQA, etc
Reading Comprehension: Benchmarked using SQuaD, BoolQ, etc.
Programming: Assessed with the help of HumanEval, etc.
The essence of these evaluations runs deep; they help developers decipher where their LLMs fall short in comparison to others and highlight where they excel.
The Audio Generative AI Space
Moving onto the realm of audio generative AI, we've observed impressive strides. We now have the ability to clone voices with just a sampling of 15 seconds data. Low shot voice duplication is now a reality, and these cloned voices can even express emotion, conveying phrases such as “SHIT SHIT SHIT” with the same intensity as a human speaker, as opposed to Alexa’s calmer, more composed delivery (no hard feelings, Amazon).
Companies like ElevenLabs are bringing this technology to the public, and open-source projects like Tortoise, Bark, SpearTTS, and AudioLM are gaining traction. Those well-versed in the history of voice AI will remember when software like Resemblyzer used to rule the roost.
But there's a new player that’s causing a stir—Retrieval-Based Voice Cloning (RIP autotune?). This technology lets us make AI voices sing (and speak like a reference audio). Its working principle is simple: train the model to learn phonemes and then provide a voice sample to be transformed. The tool then takes phonemes from the sample, aligns it with the learned speaker model, and creates the output. Quite a clever trick, indeed.
Here is a quick RVC sample - Shahrukh Khan’s legendary Chakde India speech in Amitabh Bacchan’s voice.
It's evident that these models are on the cusp of their defining moment—once a company open-sources its model and training recipes, a race ensues to ascertain the superior adaptation. To aid in distinguishing the best from the rest, we introduce some evaluation methods.
Mean Opinion Score
Let's now delve into the most essential evaluation measure: The Mean Opinion Score (MOS).
The MOS is a numerical method used to assess the overall quality of an experience or event based on human opinion. It's widely adopted within the telecommunications realm to gauge the quality of voice and video sessions.
The MOS is typically rated on a scale of 1, representing 'poor' quality, to 5, representing 'excellent' quality. The final MOS is the average of human-scored rankings across various individual parameters.
However, it's crucial to acknowledge that scaling MOS presents a challenge. The nature of human judgment-based scoring inherently involves subjectivity (think: humans almost never give a perfect score), making it hard to standardize on a large scale. Additionally, the need for multiple individual parameters makes it a tedious task to administer in high volumes.
This is why you need alternative evals to run this at scale.
Proposed Evals for Voice Cloning
These evaluations fall under two main categories:
Speaker Similarity: This checks if the outputted voice is similar to the voice in the training set.
Intelligibility: This test examines whether the model can produce speech that is understandable.
Preliminary versions of these evaluations are currently available in the original RVC repository, inviting those who are passionate and curious to give them a shot; we happily welcome pull requests.

Speaker Similarity
For Speaker Similarity, using speaker embeddings springs to mind first. To assess this, you can generate a test file of sufficient length and determine the cosine similarity between this file and the embeddings from the training dataset.

There are a few options of embedding models out there to consider, such as Titanet, Pyannote, and noresqa from FAIR.
It is essential to take note of the quality of embeddings, and one could potentially create multiple embeddings and then combine them to derive a robust final embedding.
Intelligibility
Moving onto evaluating Intelligibility, Automatic Speech Recognition (ASR) seems an excellent place to start. By running the model-generated voices through an ASR system, you can gauge the Word Error Rate. OpenAI Whisper is a good candidate for this task.

But do ensure that your training dataset has a balanced representation of phonemes. Through my experience with RVC models, if your dataset lacks certain phonemes, the resultant output will similarly lack those phonemes and replace them with the closest possible phonemes during the 'retrieval' step.
Thus, you might observe phoneme swaps like ba → da, ta → fa. A plausible method to identify missing phonemes is to use a phonetically balanced dataset, like the one from IIT Madras. Feed this dataset through the RVC model to examine which phoneme pairs greatly differ.
Conclusion
As we reach the end of this deep dive into voice cloning technology and its evaluation, it's evident that we're standing at the crossroads of significant advancements in AI and speech recognition. From the revolutionary low shot voice duplication to the exciting prospects of retrieval-based voice cloning, technology has certainly evolved leaps and bounds.
The strides made in open-source projects such as Tortoise, Bark, SpearTTS, and AudioLM are elevating this technology's accessibility and potential. However, as we see the shift in competition toward 'who's better,' the importance of effective evaluation measures cannot be overstated.
While the future promises more exciting advancements, careful application and persistent evaluation would remain fundamental to the development and optimization of voice cloning technology.
We have a discord community where we discuss the latest dope in audio generative ai, including these evals we discussed about.
Until next time,
WithoutWax
Tanay