

DubX: Next generation of TTS models

TTS turns written words into spoken languages that sound just like a person talking. From accessibility tools to virtual assistants, TTS has woven itself into the fabric of our daily experiences. In this blog, we will discuss DubX, a fully non-autoregressive text-to-speech system based on flow matching.
Launching New Suite of Speech Generation Models
We are launching dubX, a speech synthesis model with excellent zero-shot capabilities in more than 40+ languages. DubX can mimic any personality on the fly. With low latency, our model is excellent for dubbing in other languages.
What if we want Bobby Doel to speak in multiple languages seamlessly?
Or, Michael Clarke Duncan from Green Mile to speak in Hindi.
DubX
Inspired by the recent advancements of flow models, we propose a DiT (Diffusion Transformer) based model which does not require any complex design like duration model, text encoder, and phoneme alignment. Our model is trained on more than 25K hours of data covering 50+ languages.
Our model leverages the diffusion transformer with ConvNeXtV2 blocks to tackle better text-speech alignment during in-context learning. We trained our model on the text-guided speech-infilling task. Based on recent advances it is promising to train without phoneme-level duration predictor and can achieve higher naturalness in zero-shot generation deprecating explicit phoneme-level alignment. The entire pipeline can be further subdivided into the following steps:
Training
Given an audio–text pair (x, y), extract mel spectrogram
\(x_1\in\mathbb{R}^{F\times N}\)
Construct noisy speech and masked speech inputs:
\(\tilde{x}_t = (1-t)\,x_0 + t\,x_1,\quad \hat{x} = (1-m)\odot x_1,\)\(x_0\sim\mathcal{N}(0,I), t\sim\mathcal{U}[0,1], \quad m\in\{0,1\}^{F\times N}.\)Tokenize and pad text into extended character sequence.
\(z = (c_1,\ldots,c_M,\underbrace{\langle F\rangle,\ldots,\langle F\rangle}_{N-M})\)Train to reconstruct masked region by modeling.
\(P\bigl(m\odot x_1 \mid (1-m)\odot x_1,\,z\bigr)\approx q.\)
Inference
Reference mel xref and transcript yref for speaker characteristics and Generation text ygen for content.
\(N_{\mathrm{gen}} \approx N_{\mathrm{ref}}\times \frac{|y_{\mathrm{gen}}|}{|y_{\mathrm{ref}}|},\)Conditional Flow Sampling and integrate ODE.
\( v_t\bigl(\psi_t(x_0),c\bigr) =v_t\bigl((1-t)x_0 + t\,x_1 \mid x_{\mathrm{ref}},\,z_{\mathrm{ref}\cdot\mathrm{gen}}\bigr) \\\)\(\frac{d\psi_t(x_0)}{dt} =v_t\bigl(\psi_t(x_0),x_{\mathrm{ref}},\,z_{\mathrm{ref}\cdot\mathrm{gen}}\bigr), \quad \psi_0(x_0)=x_0,\ \psi_1(x_0)=x_1. \)Finally, discard reference portion of generated mel and convert remaining mel to waveform.
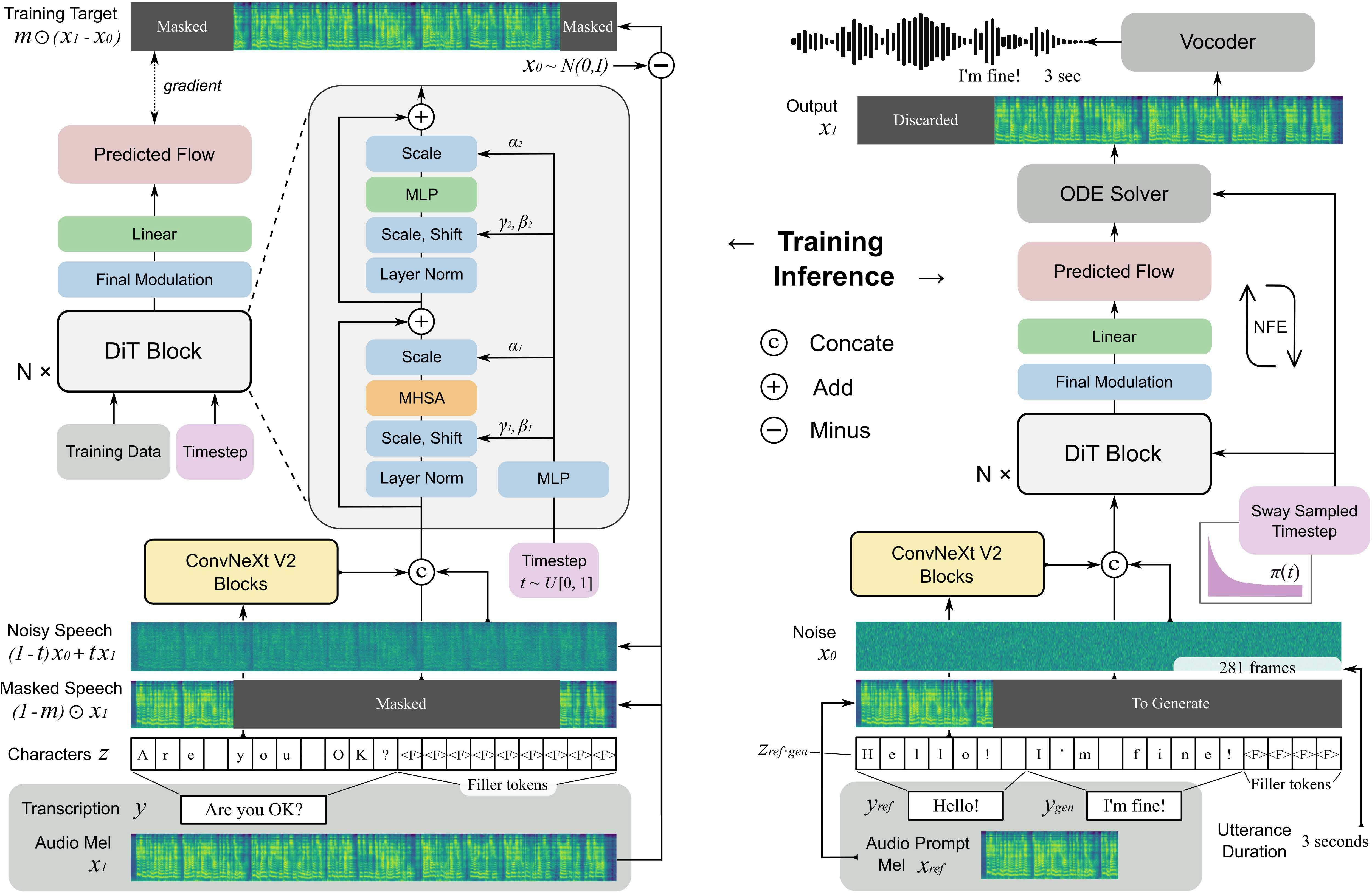
Fig 1: The entire training and Infrenece procedure of DubX model inspired by F5-TTS.
DubX journey
My journey started by using the publicly available IndicTTS model developed by AI4Bharat. I started by doing tiny experiments such as changing the reference spaker and generated text in order to gauage the performance of the model. After extensive experiments I found out that the model is producing only noise in various instances. Furthermore, the model didnot support English which is majorly spoken in parts of India. Motivated by these two problems I spearheaded the development of the Speech Synthesis models.
The entire journey can be decomposed into two parts (i) DubX V1, and (ii) DubX V2.
DubX V1
The first version of the model involves expanding the number of languages along with the training data. Fig 1. denotes the languages along with the number of hours used for each language. In total the model was trained on 2200 hours of audio data from publicly avilable sources.
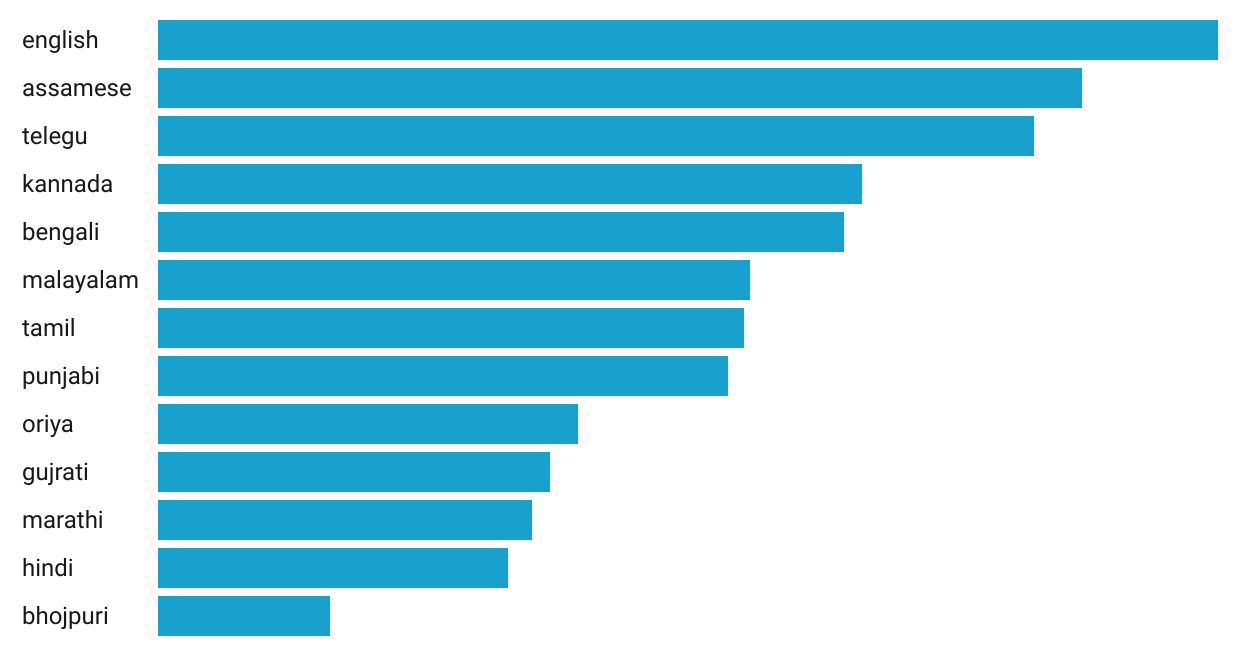
Fig 2: Languages along with their approx duration used to train V2 model
Some examples of DubX on Indian Languages using a dubverse speaker.
English
Bengali
Tamil
Telegu
Punjabi
From the above examples we can see that the model was able to seamlessly transition to multiple languages without any change in speaker. Additionally the model performs exceptionally well in code switched utterances too which I will discuss in he nex section along with examples.
DubX V2
After the succesful results from he previous version of DubX, I decided to expand the number of languages to also include foreign accents and various other Indian dialects which are generally ignored even after being spoken by millions in this country. The details on the languages used is shown in Fig 3.
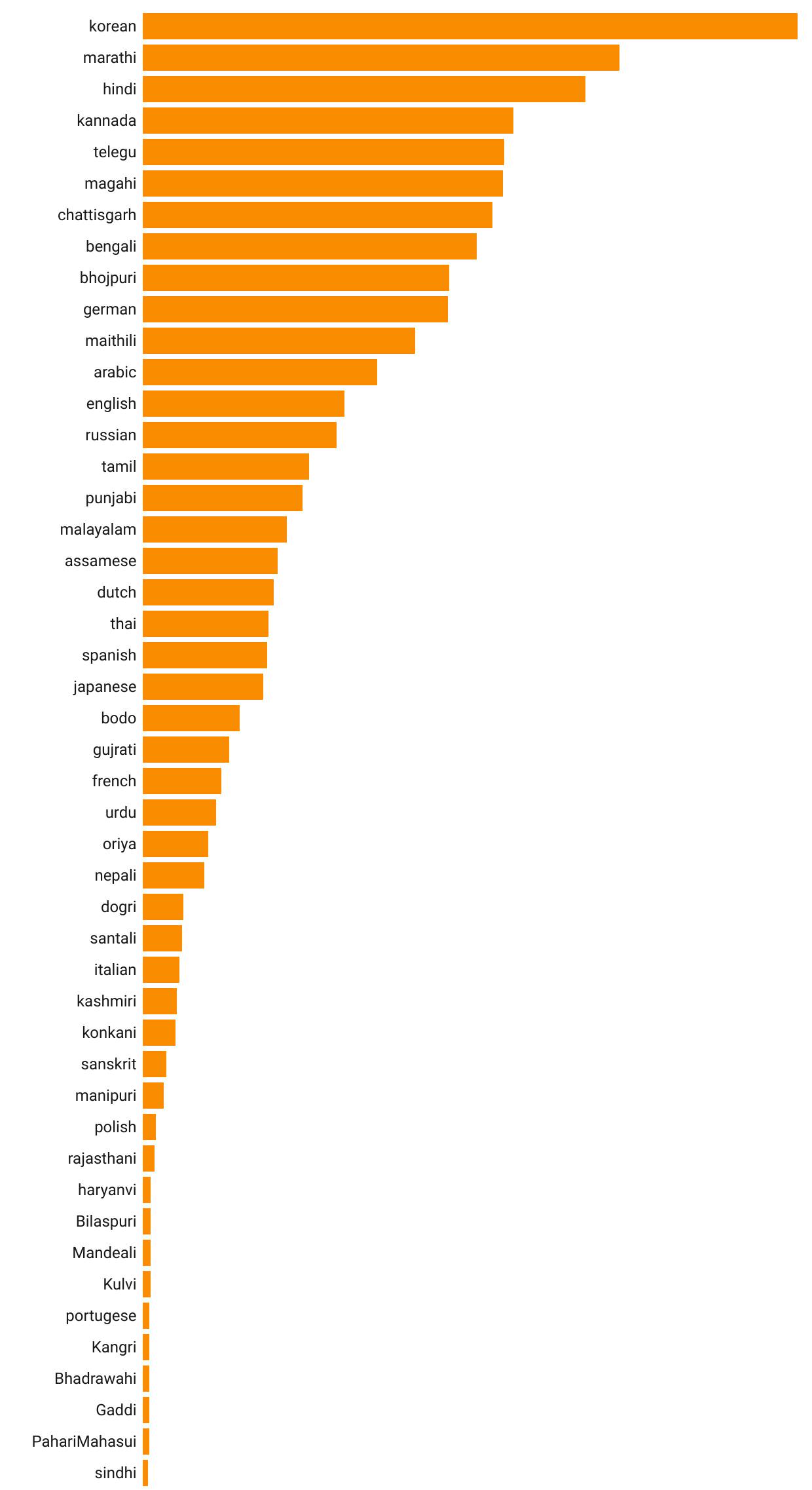
Fig 3: Languages along with their approx duration
German
Spanish
Italian
Cross-Lingual
The above audio contains phrases from multiple Indian languages including Hindi, Tamil, Bengali, Kannada, Marathi, and Malayalam
Benchmarks
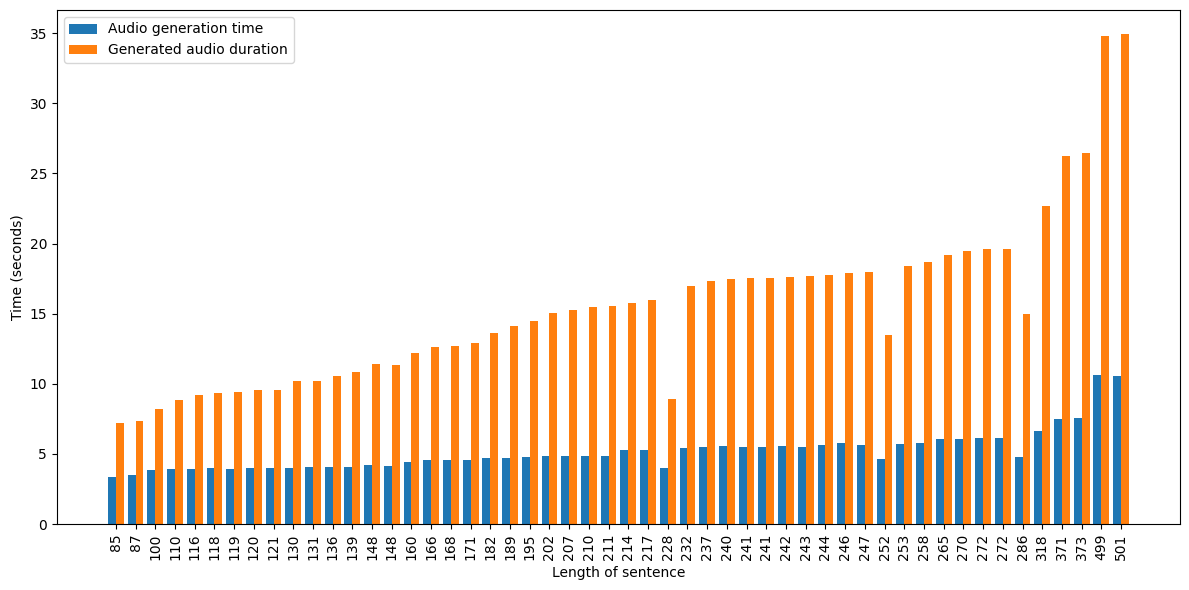
Fig 2: Plot between time taken to generate the audio and the duration of the generated audio. X-axis denotes the length of the texts and Y-axis denotes time in seconds.
Thanks for reading Amartya’s Substack! Subscribe for free to receive new posts and support my work.