

Converging to Multi-Modal Generative AI
Single Foundational Model to rule them all

The field of generative AI is evolving very quickly with new Papers and Models coming in every week ranging from text to text (GPT-4, Llama, etc.), text to image (stable Diffusion, Imagen, etc.), and text to speech (Tortoise-tts, Bark, etc.)
A common pattern among these papers emerges and that is the ability of these models to first express the semantics (Linguistics) of the modality in discrete tokens, and conditioning the text over these semantics. The second is to generate the modality (text, image, speech) back from these discrete tokens conditioned on additional information that is not present in the tokens.
Let’s Discuss this 3-step process:
Encoding to Discrete Rich SSL Representations (Tokens)
what is SSL
Self-supervised learning (SSL Blog) is a way to learn powerful representations from the data without having any human involvement. The Trick is to create synthetic labels either via lossy compression, corrupting the data and predicting the real data back, or having a bottleneck in the model itself. This is beneficial because the model will learn rich Embeddings purely using large-scale data and computing which would have been impossible to do because of the lack of humanly labeled data.
Getting SSL-based tokens for different modalities
There are already pre-trained models available that we can leverage to get the rich SSL tokens.
Text:
text is a low-bandwidth signal and hence does not require any SSL-based model to extract tokens instead it can be tokenized easily which can be done via SentencePeice, Usually, it is represented in terms of text tokens which get assigned the token embeddings which can be learned directly via training the model.
Images:
image is a high-bandwidth signal, hence its tokenization is a bit difficult task. However, VQVAE is a regularized class of Models that can learn rich discrete representations from an image. When a large amount of images are trained on the VQVAE model the codebook gets trained to retain the semantics of the image. The same technique is used in the Dalle paper
“discrete variational autoencoder (dVAE) to compress each 256×256 RGB image into a 32 × 32 grid of image tokens, each element of which can assume 8192 possible values. This reduces the context size of the transformer by a factor of 192 without a large degradation in visual quality”
The new approaches include using CLIP embeddings as tokens.
Speech:
Speech is a high-bandwidth signal, fortunately, VQVAE also works for speech. However other SSL models like Wav2Vec and Hubert also work. In Hubert, we can take continuous embedding from an intermediate layer and apply K-means on top of it. Each centroid corresponds to a higher abstract phoneme. This is not the case while using hand-engineered phonemes like CMUDict or IPA.
Decoding Tokens (conditioning)
AutoRegressive Decoding: Now that we have all the tokens (Audio + Text + Images) we can train a decoder-only transformer to and from these tokens. we can train this model on a mixture of various tasks such as:
• ASR (automatic speech recognition): transcribing the audio to obtain the transcript.• AST (automatic speech translation): translating the audio to obtain the translated transcript.
• S2ST (speech-to-speech translation): translating the audio to obtain the translated audio.
• TTS (text-to-speech): reading out the transcription to obtain the audio.
• MT (text-to-text machine translation): translating the transcript to obtain the translated transcript.
• Image Captioning (image-to-text): Describing the image to obtain the caption.
• Text-to-Image: reading out the transcription to obtain the Image.Training the model on such tasks will result in (Audio + Text + Image) tokens embedding in the same latent space. The model will have a high level of understanding of abstract concepts



Generating the Media
Generating the media back from the tokens requires powerful generative models to have a detailed output.

Diffusion Models: Gans dominated this field for a long time and are still in use in some cases. Since Gans are difficult to train and get stuck in the mode of the dataset. Diffusion models offer a compute-intensive approach to solve the above two problems. Diffusion Models are built on first noisyfying the input over timesteps of T and then training the model to predict the noise back added at timestep t from the input at t+1, having 3 constraints.
1. At the end of the timestep T, the input becomes Gaussian noise
2. The reconstruction loss of the input should be minimized
3. The KL Divergence of the input noise to the predicted noise should be minimized.
Text: Generating text back from the tokens can be done by the de-tokenization process.
Speech: Generating speech back from the tokens is a tough task, and we can train a diffusion model conditioned on the semantic tokens and the Speaker information that is not present in the tokens. Other architectures like FastSpeech can also work, but it requires finetuning vocoder separately on the output of the Fastspeech generated Melspecs as it is not a powerful generative model.
Image: Generating Images from the tokens can be done by the VQVAE decoder as well, but again the VQVAE decoder is not a powerful generative model and hence the output images are not of quality. Here we can train the Diffusion/Gan model conditioned on the Image tokens to produce quality images from the tokens.
Combining the Modalities
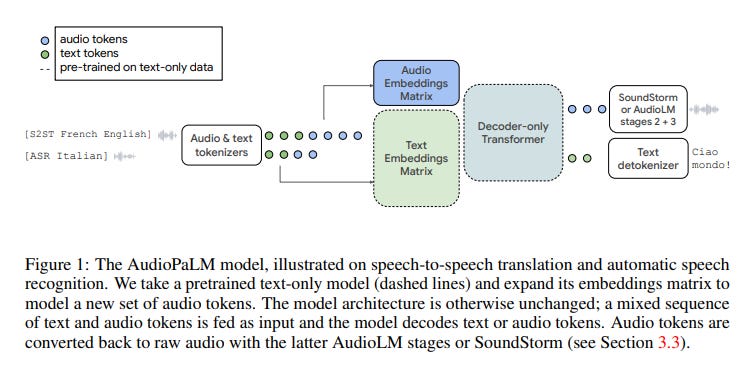
paper - AudioPalm (Combining speech and text in a single architecture)
AudioPalm uses SentencePiece Text tokenizer and w2v-bert + k-means Audio tokenizer, they have also experimented with USM-v1 and USM-v2 for audio tokenization.
Types of tasks AudioPalm trained on: All datasets used in this report are speech-text datasets which contain a
a subset of the following fields.
• Audio: speech in the source language.
• Transcript: a transcript of the speech in Audio.
• Translated audio: the spoken translation of the speech in Audio.
• Translated transcript: the written translation of the speech in Audio.
The component tasks that we consider in this report are:
• ASR (automatic speech recognition): transcribing the audio to obtain the transcript.
• AST (automatic speech translation): translating the audio to obtain the translated transcript.
• S2ST (speech-to-speech translation): translating the audio to obtain the translated audio.
• TTS (text-to-speech): reading out the transcription to obtain the audio.
• MT (text-to-text machine translation): translating the transcript to obtain the translated
transcript.
As mentioned in the paper.
In terms of Audio Decoder, Audio Palm has used two decoders
1. AudioLm which is an Autoregressive decoder.
2. SoundStorm Decoder which is a Masked Git decoder.
AudioPalm 1B sized model outperforms Whisper 1.5B Large model by over 5 BLEU points and 28% reduction in WER for VoxPopuli ASR.
SeamlessM4T is a recent Architecture that uses a similar concept except its decoder-only transformer only outputs text tokens.
It would be interesting to see how the above concept will work at a video level with all three modalities combined.
Join our Discord community to get the scoop on the latest in Audio Generative AI!
Hope you liked this edition of Dubverse Black.
Until Next Time,
Jaskaran